

La era de la IA está pasando del entrenamiento a la inferencia. El GTC 2026 de NVIDIA reforzó la idea de que el verdadero valor de la IA se genera cada vez más cuando los modelos funcionan de forma continua en producción, cerca de las fuentes de datos, ofreciendo menor latencia, mejor eficiencia económica y un mayor control sobre los datos.
El mercado global de Edge AI está en pleno crecimiento, con previsiones de pasar de 11.800 millones de dólares en 2025 a 56.800 millones en 2030, con una tasa de crecimiento anual compuesta del 36,9%, impulsado por la necesidad de inferencia en tiempo real en entornos sensibles a la privacidad, de baja latencia, y también por factores geopolíticos.
Para las empresas, este cambio redefine la conversación sobre arquitectura de IA. La pregunta ya no es solo cómo construir LLMs, sino cómo hacerlos más rápidos, más baratos, más seguros y disponibles en cualquier lugar —desde la nube pública o privada hasta el edge—. Aquí es donde la optimización de modelos pasa de ser opcional a convertirse en un activo estratégico.
Tecnologías de optimización de IA
Entre las tecnologías actuales, destacan varios enfoques clave:
- Optimizadores de prompts, como Compression Cloud, que evitan modificar el modelo optimizando los prompts para reducir el consumo de tokens.
- Cuantización, que reduce la precisión numérica para disminuir el uso de memoria y acelerar la inferencia, normalmente con cierto impacto en la precisión.
- Optimizadores de procesador, como OptAI, que mediante cuantización optimizan CPUs y NPUs sustituyendo kernels por runtimes personalizados aplicables a cualquier modelo.
- Pruning, que elimina pesos o neuronas menos relevantes para reducir el tamaño del modelo y el cómputo necesario.
- Distillation, que transfiere conocimiento de un modelo grande a uno más pequeño.
- Adaptación de bajo rango y fine-tuning eficiente en parámetros, que hacen la adaptación más ligera y práctica.
- Compresión basada en redes tensor, que va más allá de los enfoques tradicionales reduciendo estructuralmente la complejidad del modelo.
- Almacenamiento de alta velocidad, como los nuevos SSD de Kioxia, que eliminan cuellos de botella entre CPU y almacenamiento para un acceso más rápido a tensores.
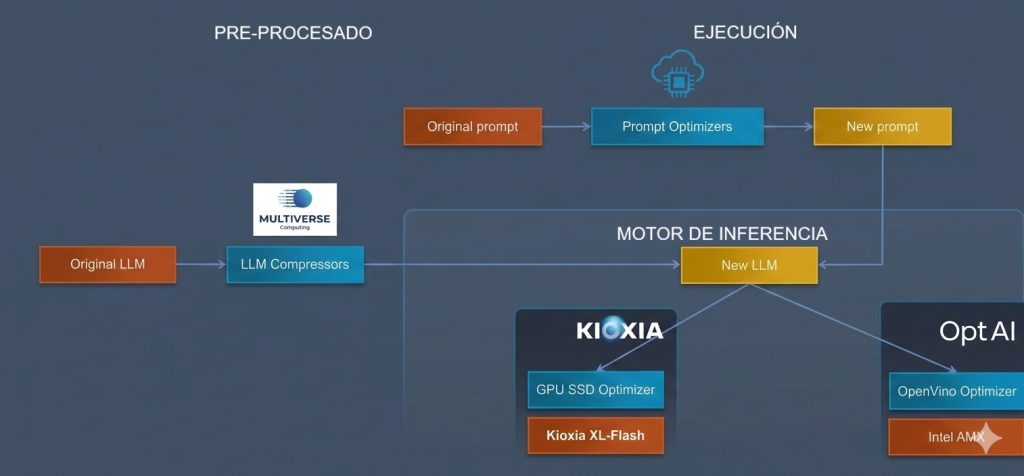
En este contexto, destaca especialmente CompactifAI de Multiverse Computing, por su enfoque diferencial basado en redes tensor avanzadas para comprimir LLMs, haciéndolos más rápidos, económicos, eficientes energéticamente y portables entre distintos entornos operativos.
Resolviendo los retos del despliegue en el Edge
Lo que hace especialmente relevante este enfoque en el edge es su impacto operativo. Los modelos comprimidos, al ser más pequeños, pueden ejecutarse en hardware menos potente —como drones—, reducen los requisitos de disco y memoria, mejoran los tiempos de respuesta y ayudan a mantener los datos en local.
La “magia” está en reducir significativamente el tamaño de los LLMs sin perder fiabilidad en las respuestas. De lo contrario, los SLMs (modelos pequeños) serían una opción más lógica.
Las organizaciones que consigan desplegar el modelo adecuado, en el lugar adecuado y con el coste adecuado, liderarán la próxima ola de la IA.
En la práctica, esto se traduce en mejores costes de inferencia en el edge, menor consumo energético y mayor viabilidad en entornos limitados, como escenarios de operaciones en condiciones extremas o de recursos restringidos.
Sectores clave beneficiados
Más allá del ámbito de la defensa, este avance impacta en múltiples sectores:
- Sector público y soberanía digital, donde la residencia de datos, la gobernanza y el control operativo son críticos. Ejemplo: detección de violencia en tiempo real mediante visión artificial en sistemas CCTV en las ciudades.
- Sanidad, donde la privacidad y la necesidad de decisiones en tiempo real se benefician de la inferencia local.
- Industria y fabricación, con casos como inspección de calidad, mantenimiento predictivo, seguridad laboral y aplicaciones de IA física (robótica).
- Consumo y espacios inteligentes, donde la personalización en tiempo real y el análisis de vídeo requieren procesamiento local rápido. Ejemplo: reducción de colas en caja para mejorar la experiencia del cliente.
- Telecomunicaciones y proveedores de servicios, donde la inferencia distribuida como servicio permite monetizar infraestructuras edge desde nodos de comunicaciones para así reducir las latencias.
Los proyectos de Edge AI sólo alcanzan economía de escala cuando consiguen volumen. Para lograrlo, los equipos deben invertir de forma estratégica, aprovechando la compresión de modelos para entregar despliegues a tiempo, dentro de presupuesto y con alta calidad.
Pero este concepto va más allá del edge. Los optimizadores de modelos también son críticos en centros de datos, donde los ciclos de GPU en factorías de IA son un recurso valioso. Cada mejora en eficiencia mediante compresión se multiplica a través de miles de cargas de inferencia, reduciendo costes y maximizando el rendimiento.








